 2 days ago
3
2 days ago
3
Club.noww.in
 Image credit: Adobe Stock.
Image credit: Adobe Stock.Fundamental choices impacting integration and deployment at scale of GenAI into businesses
Before a company or a developer adopts generative artificial intelligence (GenAI), they often wonder how to get business value from the integration of AI into their business. With this in mind, a fundamental question arises: Which approach will deliver the best value on investment — a large all-encompassing proprietary model or an open source AI model that can be molded and fine-tuned for a company’s needs? AI adoption strategies fall within a wide spectrum, from accessing a cloud service from a large proprietary frontier model like OpenAI’s GPT-4o to building an internal solution in the company’s compute environment with an open source small model using indexed company data for a targeted set of tasks. Current AI solutions go well beyond the model itself, with a whole ecosystem of retrieval systems, agents, and other functional components such as AI accelerators, which are beneficial for both large and small models. Emergence of cross-industry collaborations like the Open Platform for Enterprise AI (OPEA) further the promise of streamlining the access and structuring of end-to-end open source solutions.
This basic choice between the open source ecosystem and a proprietary setting impacts countless business and technical decisions, making it “the AI developer’s dilemma.” I believe that for most enterprise and other business deployments, it makes sense to initially use proprietary models to learn about AI’s potential and minimize early capital expenditure (CapEx). However, for broad sustained deployment, in many cases companies would use ecosystem-based open source targeted solutions, which allows for a cost-effective, adaptable strategy that aligns with evolving business needs and industry trends.
GenAI Transition from Consumer to Business Deployment
When GenAI burst onto the scene in late 2022 with Open AI’s GPT-3 and ChatGPT 3.5, it mainly garnered consumer interest. As businesses began investigating GenAI, two approaches to deploying GenAI quickly emerged in 2023 — using giant frontier models like ChatGPT vs. the newly introduced small, open source models originally inspired by Meta’s LLaMa model. By early 2024, two basic approaches have solidified, as shown in the columns in Figure 1. With the proprietary AI approach, the company relies on a large closed model to provide all the needed technology value. For example, taking GPT-4o as a proxy for the left column, AI developers would use OpenAI technology for the model, data, security, and compute. With the open source ecosystem AI approach, the company or developer may opt for the right-sized open source model, using corporate or private data, customized functionality, and the necessary compute and security.
Both directions are valid and have advantages and disadvantages. It is not an absolute partition and developers can choose components from either approach, but taking either a proprietary or ecosystem-based open source AI path provides the company with a strategy with high internal consistency. While it is expected that both approaches will be broadly deployed, I believe that after an initial learning and transition period, most companies will follow the open source approach. Depending on the usage and setting, open source internal AI may provide significant benefits, including the ability to fine-tune the model and drive deployment using the company’s current infrastructure to run the model at the edge, on the client, in the data center, or as a dedicated service. With new AI fine-tuning tools, deep expertise is less of a barrier.
 Figure 1. Base approaches to the AI developer’s dilemma. Image credit: Intel Labs.
Figure 1. Base approaches to the AI developer’s dilemma. Image credit: Intel Labs.Across all industries, AI developers are using GenAI for a variety of applications. An October 2023 poll by Gartner found that 55% of organizations reported increasing investment in GenAI since early 2023, and many companies are in pilot or production mode for the growing technology. As of the time of the survey, companies were mainly investing in using GenAI for software development, followed closely by marketing and customer service functions. Clearly, the range of AI applications is growing rapidly.
Large Proprietary Models vs. Small and Large Open Source Models
 Figure 2: Advantages of large proprietary models, and small and large open source models. For business considerations, see Figure 7 for CapEx and OpEx aspects. Image credit: Intel Labs.
Figure 2: Advantages of large proprietary models, and small and large open source models. For business considerations, see Figure 7 for CapEx and OpEx aspects. Image credit: Intel Labs.In my blog Survival of the Fittest: Compact Generative AI Models Are the Future for Cost-Effective AI at Scale, I provide a detailed evaluation of large models vs. small models. In essence, following the introduction of Meta’s LLaMa open source model in February 2023, there has been a virtuous cycle of innovation and rapid improvement where the academia and broad-base ecosystem are creating highly effective models that are 10x to 100x smaller than the large frontier models. A crop of small models, which in 2024 were mostly less than 30 billion parameters, could closely match the capabilities of ChatGPT-style large models containing well over 100B parameters, especially when targeted for particular domains. While GenAI is already being deployed throughout industries for a wide range of business usages, the use of compact models is rising.
In addition, open source models are mostly lagging only six to 12 months behind the performance of proprietary models. Using the broad language benchmark MMLU, the improvement pace of the open source models is faster and the gap seems to be closing with proprietary models. For example, OpenAI’s GPT-4o came out this year on May 13 with major multimodal features while Microsoft’s small open source Phi-3-vision was introduced just a week later on May 21. In rudimentary comparisons done on visual recognition and understanding, the models showed some similar competencies, with several tests even favoring the Phi-3-vision model. Initial evaluations of Meta’s Llama 3.2 open source release suggest that its “vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks.”
Large models have incredible all-in-one versatility. Developers can choose from a variety of large commercially available proprietary GenAI models, including OpenAI’s GPT-4o multimodal model. Google’s Gemini 1.5 natively multimodal model is available in four sizes: Nano for mobile device app development, Flash small model for specific tasks, Pro for a wide range of tasks, and Ultra for highly complex tasks. And Anthropic’s Claude 3 Opus, rumored to have approximately 2 trillion parameters, has a 200K token context window, allowing users to upload large amounts of information. There’s also another category of out-of-the-box large GenAI models that businesses can use for employee productivity and creative development. Microsoft 365 Copilot integrates the Microsoft 365 Apps suite, Microsoft Graph (content and context from emails, files, meetings, chats, calendars, and contacts), and GPT-4.
Most large and small open source models are often more transparent about application frameworks, tool ecosystem, training data, and evaluation platforms. Model architecture, hyperparameters, response quality, input modalities, context window size, and inference cost are partially or fully disclosed. These models often provide information on the dataset so that developers can determine if it meets copyright or quality expectations. This transparency allows developers to easily interchange models for future versions. Among the growing number of small commercially available open source models, Meta’s Llama 3 and 3.1 are based on transformer architecture and available in 8B, 70B, and 405B parameters. Llama 3.2 multimodal model has 11B and 90B, with smaller versions at 1B and 3B parameters. Built in collaboration with NVIDIA, Mistral AI’s Mistral NeMo is a 12B model that features a large 128k context window while Microsoft’s Phi-3 (3.8B, 7B, and 14B) offers Transformer models for reasoning and language understanding tasks. Microsoft highlights Phi models as an example of “the surprising power of small language models” while investing heavily in OpenAI’s very large models. Microsoft’s diverse interest in GenAI indicates that it’s not a one-size-fits-all market.
Model-Incorporated Data (with RAG) vs. Retrieval-Centric Generation (RCG)
The next key question that AI developers need to address is where to find the data used during inference — within the model parametric memory or outside the model (accessible by retrieval). It might be hard to believe, but the first ChatGPT launched in November 2022 did not have any access to data outside the model. It was trained on September 21, 2022 and notoriously had no inclination of events and data past its training date. This major oversight was addressed in 2023 when retrieval plug-ins where added. Today, most models are coupled with a retrieval front-end with exceptions in cases where there is no expectation of accessing large or continuously updating information, such as dedicated programming models.
Current models have made significant progress on this issue by enhancing the solution platforms with a retrieval-augmented generation (RAG) front-end to allow for extracting information external to the model. An efficient and secure RAG is a requirement in enterprise GenAI deployment, as shown by Microsoft’s introduction of GPT-RAG in late 2023. Furthermore, in the blog Knowledge Retrieval Takes Center Stage, I cover how in the transition from consumer to business deployment for GenAI, solutions should be built primarily around information external to the model using retrieval-centric generation (RCG).
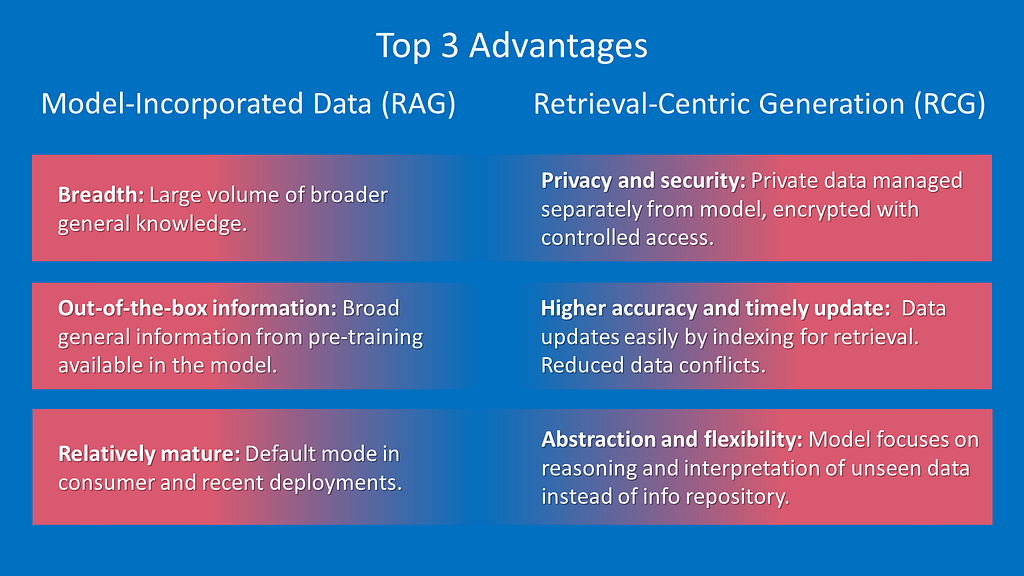 Figure 3. Advantage of RAG vs. RCG. Image credit: Intel Labs.
Figure 3. Advantage of RAG vs. RCG. Image credit: Intel Labs.RCG models can be defined as a special case of RAG GenAI solutions designed for systems where the vast majority of data resides outside the model parametric memory and is mostly not seen in pre-training or fine-tuning. With RCG, the primary role of the GenAI model is to interpret rich retrieved information from a company’s indexed data corpus or other curated content. Rather than memorizing data, the model focuses on fine-tuning for targeted constructs, relationships, and functionality. The quality of data in generated output is expected to approach 100% accuracy and timeliness.
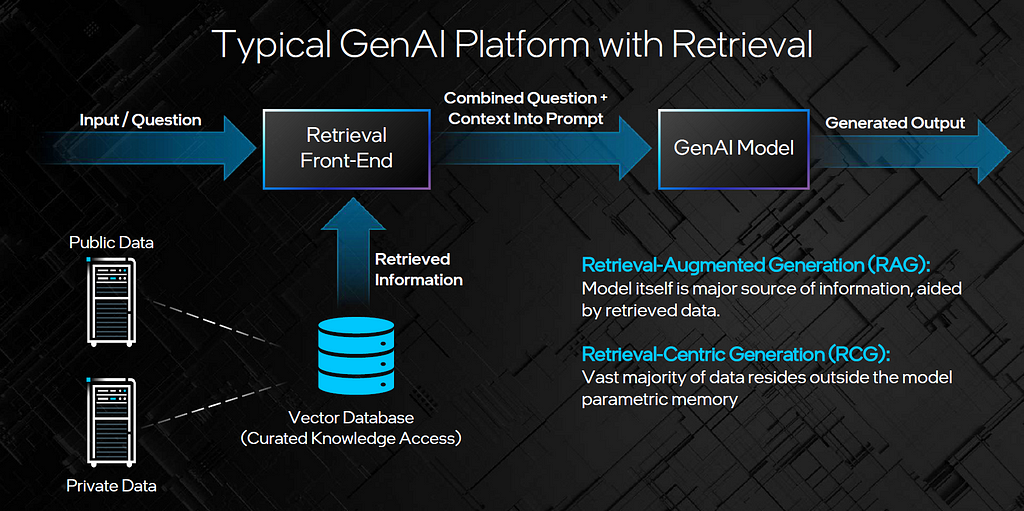 Figure 4. How retrieval works in GenAI platforms. Image credit: Intel Labs.
Figure 4. How retrieval works in GenAI platforms. Image credit: Intel Labs.OPEA is a cross-ecosystem effort to ease the adoption and tuning of GenAI systems. Using this composable framework, developers can create and evaluate “open, multi-provider, robust, and composable GenAI solutions that harness the best innovation across the ecosystem.” OPEA is expected to simplify the implementation of enterprise-grade composite GenAI solutions, including RAG, agents, and memory systems.
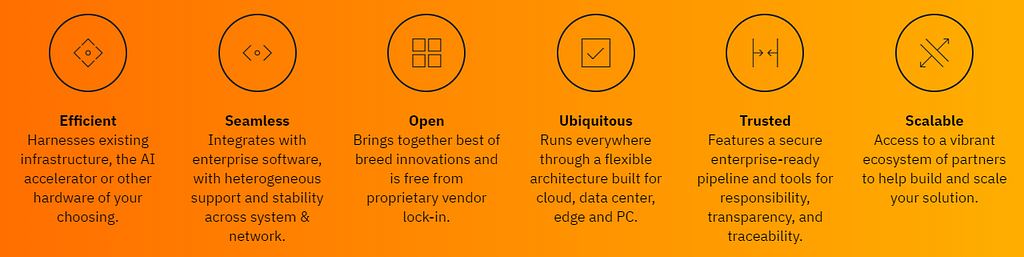 Figure 5. OPEA core principles for GenAI implementation. Image credit: OPEA.
Figure 5. OPEA core principles for GenAI implementation. Image credit: OPEA.All-in-One General Purpose vs. Targeted Customized Models
Models like GPT-4o, Claude 3, and Gemini 1.5 are general purpose all-in-one foundation models. They are designed to perform a broad range of GenAI from coding to chat to summarization. The latest models have rapidly expanded to perform vision/image tasks, changing their function from just large language models to large multimodal models or vision language models (VLMs). Open source foundation models are headed in the same direction as integrated multimodalities.
 Figure 6. Advantages of general purpose vs. targeted customized models. Image credit: Intel Labs.
Figure 6. Advantages of general purpose vs. targeted customized models. Image credit: Intel Labs.However, rather than adopting the first wave of consumer-oriented GenAI models in this general-purpose form, most businesses are electing to use some form of specialization. When a healthcare company deploys GenAI technology, they would not use one general model for managing the supply chain, coding in the IT department, and deep medical analytics for managing patient care. Businesses deploy more specialized versions of the technology for each use case. There are several different ways that companies can build specialized GenAI solutions, including domain-specific models, targeted models, customized models, and optimized models.
Domain-specific models are specialized for a particular field of business or an area of interest. There are both proprietary and open source domain-specific models. For example, BloombergGPT, a 50B parameter proprietary large language model specialized for finance, beats the larger GPT-3 175B parameter model on various financial benchmarks. However, small open source domain-specific models can provide an excellent alternative, as demonstrated by FinGPT, which provides accessible and transparent resources to develop FinLLMs. FinGPT 3.3 uses Llama 2 13B as a base model targeted for the financial sector. In recent benchmarks, FinGPT surpassed BloombergGPT on a variety of tasks and beat GPT-4 handily on financial benchmark tasks like FPB, FiQA-SA, and TFNS. To understand the tremendous potential of this small open source model, it should be noted that FinGPT can be fine-tuned to incorporate new data for less than $300 per fine-tuning.
Targeted models specialize in a family of tasks or functions, such as separate targeted models for coding, image generation, question answering, or sentiment analysis. A recent example of a targeted model is SetFit from Intel Labs, Hugging Face, and the UKP Lab. This few-shot text classification approach for fine-tuning Sentence Transformers is faster at inference and training, achieving high accuracy with a small number of labeled training data, such as only eight labeled examples per class on the Customer Reviews (CR) sentiment dataset. This small 355M parameter model can best the GPT-3 175B parameter model on the diverse RAFT benchmark.
It’s important to note that targeted models are independent from domain-specific models. For example, a sentiment analysis solution like SetFitABSA has targeted functionality and can be applied to various domains like industrial, entertainment, or hospitality. However, models that are both targeted and domain specialized can be more effective.
Customized models are further fine-tuned and refined to meet particular needs and preferences of companies, organizations, or individuals. By indexing particular content for retrieval, the resulting system becomes highly specific and effective on tasks related to this data (private or public). The open source field offers an array of options to customize the model. For example, Intel Labs used direct preference optimization (DPO) to improve on a Mistral 7B model to create the open source Intel NeuralChat. Developers also can fine-tune and customize models by using low-rank adaptation of large language (LoRA) models and its more memory-efficient version, QLoRA.
Optimization capabilities are available for open source models. The objective of optimization is to retain the functionality and accuracy of a model while substantially reducing its execution footprint, which can significantly improve cost, latency, and optimal execution of an intended platform. Some techniques used for model optimization include distillation, pruning, compression, and quantization (to 8-bit and even 4-bit). Some methods like mixture of experts (MoE) and speculative decoding can be considered as forms of execution optimization. For example, GPT-4 is reportedly comprised of eight smaller MoE models with 220B parameters. The execution only activates parts of the model, allowing for much more economical inference.
Generative-as-a-Service Cloud Execution vs. Managed Execution Environment for Inference
 Figure 7. Advantages of GaaS vs. managed execution. Image credit: Intel Labs.
Figure 7. Advantages of GaaS vs. managed execution. Image credit: Intel Labs.Another key choice for developers to consider is the execution environment. If the company chooses a proprietary model direction, inference execution is done through API or query calls to an abstracted and obscured image of the model running in the cloud. The size of the model and other implementation details are insignificant, except when translated to availability and the cost charged by some key (per token, per query, or unlimited compute license). This approach, sometimes referred to as a generative-as-a-service (GaaS) cloud offering, is the principle way for companies to consume very large proprietary models like GPT-4o, Gemini Ultra, and Claude 3. However, GaaS can also be offered for smaller models like Llama 3.2.
There are clear positive aspects to using GaaS for the outsourced intelligence approach. For example, the access is usually instantaneous and easy to use out-of-the-box, alleviating in-house development efforts. There is also the implied promise that when the models or their environment get upgraded, the AI solution developers have access to the latest updates without substantial effort or changes to their setup. Also, the costs are almost entirely operational expenditures (OpEx), which is preferred if the workload is initial or limited. For early-stage adoption and intermittent use, GaaS offers more support.
In contrast, when companies choose an internal intelligence approach, the model inference cycle is incorporated and managed within the compute environment and the existing business software setting. This is a viable solution for relatively small models (approximately 30B parameters or less in 2024) and potentially even medium models (50B to 70B parameters in 2024) on a client device, network, on-prem data center, or on-cloud cycles in an environment set with a service provider such as a virtual private cloud (VPC).
Models like Llama 3.1 8B or similar can run on the developer’s local machine (Mac or PC). Using optimization techniques like quantization, the needed user experience can be achieved while operating within the local setting. Using a tool and framework like Ollama, developers can manage inference execution locally. Inference cycles can be run on legacy GPUs, Intel Xeon, or Intel Gaudi AI accelerators in the company’s data center. If inference is run on the model at a service provider, it will be billed as infrastructure-as-a-service (IaaS), using the company’s own setting and execution choices.
When inference execution is done in the company compute environment (client, edge, on-prem, or IaaS), there is a higher requirement for CapEx for ownership of the computer equipment if it goes beyond adding a workload to existing hardware. While the comparison of OpEx vs. CapEx is complex and depends on many variables, CapEx is preferable when deployment requires broad, continuous, stable usage. This is especially true as smaller models and optimization technologies allow for running advanced open source models on mainstream devices and processors and even local notebooks/desktops.
Running inference in the company compute environment allows for tighter control over aspects of security and privacy. Reducing data movement and exposure can be valuable in preserving privacy. Furthermore, a retrieval-based AI solution run in a local setting can be supported with fine controls to address potential privacy concerns by giving user-controlled access to information. Security is frequently mentioned as one of the top concerns of companies deploying GenAI and confidential computing is a primary ask. Confidential computing protects data in use by computing in an attested hardware-based Trusted Execution Environment (TEE).
Smaller, open source models can run within a company’s most secure application setting. For example, a model running on Xeon can be fully executed within a TEE with limited overhead. As shown in Figure 8, encrypted data remains protected while not in compute. The model is checked for provenance and integrity to protect against tampering. The actual execution is protected from any breach, including by the operating system or other applications, preventing viewing or alteration by untrusted entities.
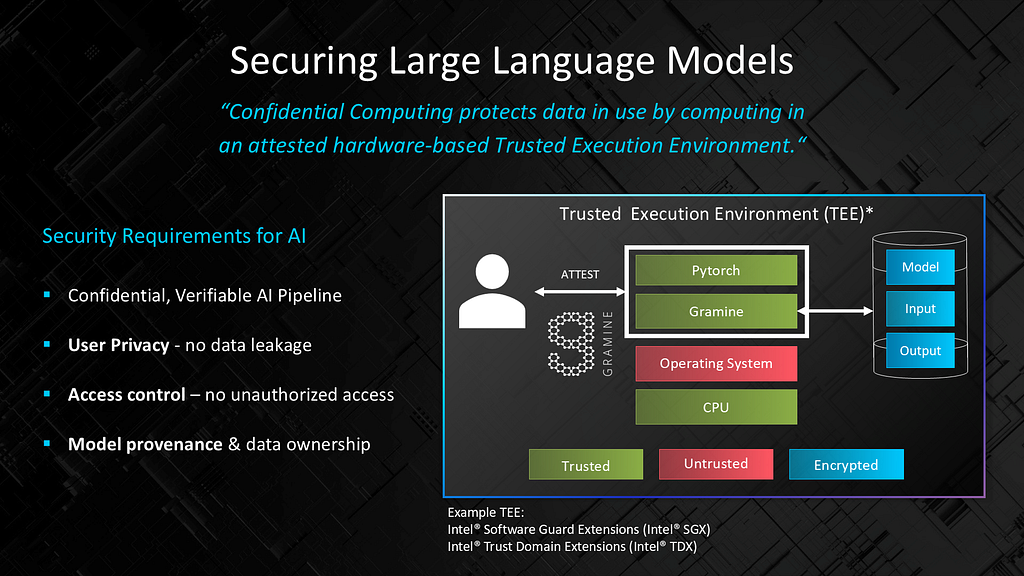 Figure 8. Security requirements for GenAI. Image credit: Intel Labs.
Figure 8. Security requirements for GenAI. Image credit: Intel Labs.Summary
Generative AI is a transformative technology now under evaluation or active adoption by most companies across all industries and sectors. As AI developers consider their options for the best solution, one of the most important questions they need to address is whether to use external proprietary models or rely on the open source ecosystem. One path is to rely on a large proprietary black-box GaaS solution using RAG, such as GPT-4o or Gemini Ultra. The other path uses a more adaptive and integrative approach — small, selected, and exchanged as needed from a large open source model pool, mainly utilizing company information, customized and optimized based on particular needs, and executed within the existing infrastructure of the company. As mentioned, there could be a combination of choices within these two base strategies.
I believe that as numerous AI solution developers face this essential dilemma, most will eventually (after a learning period) choose to embed open source GenAI models in their internal compute environment, data, and business setting. They will ride the incredible advancement of the open source and broad ecosystem virtuous cycle of AI innovation, while maintaining control over their costs and destiny.
Let’s give AI the final word in solving the AI developer’s dilemma. In a staged AI debate, OpenAI’s GPT-4 argued with Microsoft’s open source Orca 2 13B on the merits of using proprietary vs. open source GenAI for future development. Using GPT-4 Turbo as the judge, open source GenAI won the debate. The winning argument? Orca 2 called for a “more distributed, open, collaborative future of AI development that leverages worldwide talent and aims for collective advancements. This model promises to accelerate innovation and democratize access to AI, and ensure ethical and transparent practices through community governance.”
Learn More: GenAI Series
Survival of the Fittest: Compact Generative AI Models Are the Future for Cost-Effective AI at Scale
Have Machines Just Made an Evolutionary Leap to Speak in Human Language?
References
- Hello GPT-4o. (2024, May 13). https://openai.com/index/hello-gpt-4o/
- Open platform for enterprise AI. (n.d.). Open Platform for Enterprise AI (OPEA). https://opea.dev/
- Gartner Poll Finds 55% of Organizations are in Piloting or Production. (2023, October 3). Gartner. https://www.gartner.com/en/newsroom/press-releases/2023-10-03-gartner-poll-finds-55-percent-of-organizations-are-in-piloting-or-production-mode-with-generative-ai
- Singer, G. (2023, July 28). Survival of the fittest: Compact generative AI models are the future for Cost-Effective AI at scale. Medium. https://towardsdatascience.com/survival-of-the-fittest-compact-generative-ai-models-are-the-future-for-cost-effective-ai-at-scale-6bbdc138f618
- Introducing LLaMA: A foundational, 65-billion-parameter language model. (n.d.). https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- #392: OpenAI’s improved ChatGPT should delight both expert and novice developers, & more — ARK Invest. (n.d.). Ark Invest. https://ark-invest.com/newsletter_item/1-openais-improved-chatgpt-should-delight-both-expert-and-novice-developers
- Bilenko, M. (2024, May 22). New models added to the Phi-3 family, available on Microsoft Azure. Microsoft Azure Blog. https://azure.microsoft.com/en-us/blog/new-models-added-to-the-phi-3-family-available-on-microsoft-azure/
- Matthew Berman. (2024, June 2). Open-Source Vision AI — Surprising Results! (Phi3 Vision vs LLaMA 3 Vision vs GPT4o) [Video]. YouTube. https://www.youtube.com/watch?v=PZaNL6igONU
- Llama 3.2: Revolutionizing edge AI and vision with open, customizable models. (n.d.). https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
- Gemini — Google DeepMind. (n.d.). https://deepmind.google/technologies/gemini/#introduction
- Introducing the next generation of Claude \ Anthropic. (n.d.). https://www.anthropic.com/news/claude-3-family
- Thompson, A. D. (2024, March 4). The Memo — Special edition: Claude 3 Opus. The Memo by LifeArchitect.ai. https://lifearchitect.substack.com/p/the-memo-special-edition-claude-3
- Spataro, J. (2023, May 16). Introducing Microsoft 365 Copilot — your copilot for work — The Official Microsoft Blog. The Official Microsoft Blog. https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/
- Introducing Llama 3.1: Our most capable models to date. (n.d.). https://ai.meta.com/blog/meta-llama-3-1/
- Mistral AI. (2024, March 4). Mistral Nemo. Mistral AI | Frontier AI in Your Hands. https://mistral.ai/news/mistral-nemo/
- Beatty, S. (2024, April 29). Tiny but mighty: The Phi-3 small language models with big potential. Microsoft Research. https://news.microsoft.com/source/features/ai/the-phi-3-small-language-models-with-big-potential/
- Hughes, A. (2023, December 16). Phi-2: The surprising power of small language models. Microsoft Research. https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
- Azure. (n.d.). GitHub — Azure/GPT-RAG. GitHub. https://github.com/Azure/GPT-RAG/
- Singer, G. (2023, November 16). Knowledge Retrieval Takes Center Stage — Towards Data Science. Medium. https://towardsdatascience.com/knowledge-retrieval-takes-center-stage-183be733c6e8
- Introducing the open platform for enterprise AI. (n.d.). Intel. https://www.intel.com/content/www/us/en/developer/articles/news/introducing-the-open-platform-for-enterprise-ai.html
- Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., & Mann, G. (2023, March 30). BloombergGPT: A large language model for finance. arXiv.org. https://arxiv.org/abs/2303.17564
- Yang, H., Liu, X., & Wang, C. D. (2023, June 9). FINGPT: Open-Source Financial Large Language Models. arXiv.org. https://arxiv.org/abs/2306.06031
- AI4Finance-Foundation. (n.d.). FinGPT. GitHub. https://github.com/AI4Finance-Foundation/FinGPT
- Starcoder2. (n.d.). GitHub. https://huggingface.co/docs/transformers/v4.39.0/en/model_doc/starcoder2
- SetFit: Efficient Few-Shot Learning Without Prompts. (n.d.). https://huggingface.co/blog/setfit
- SetFitABSA: Few-Shot Aspect Based Sentiment Analysis Using SetFit. (n.d.). https://huggingface.co/blog/setfit-absa
- Intel/neural-chat-7b-v3–1. Hugging Face. (2023, October 12). https://huggingface.co/Intel/neural-chat-7b-v3-1
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021, June 17). LORA: Low-Rank adaptation of Large Language Models. arXiv.org. https://arxiv.org/abs/2106.09685
- Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023, May 23). QLORA: Efficient Finetuning of Quantized LLMS. arXiv.org. https://arxiv.org/abs/2305.14314
- Leviathan, Y., Kalman, M., & Matias, Y. (2022, November 30). Fast Inference from Transformers via Speculative Decoding. arXiv.org. https://arxiv.org/abs/2211.17192
- Bastian, M. (2023, July 3). GPT-4 has more than a trillion parameters — Report. THE DECODER. https://the-decoder.com/gpt-4-has-a-trillion-parameters/
- Andriole, S. (2023, September 12). LLAMA, ChatGPT, Bard, Co-Pilot & all the rest. How large language models will become huge cloud services with massive ecosystems. Forbes. https://www.forbes.com/sites/steveandriole/2023/07/26/llama-chatgpt-bard-co-pilot--all-the-rest--how-large-language-models-will-become-huge-cloud-services-with-massive-ecosystems/?sh=78764e1175b7
- Q8-Chat LLM: An efficient generative AI experience on Intel® CPUs. (n.d.). Intel. https://www.intel.com/content/www/us/en/developer/articles/case-study/q8-chat-efficient-generative-ai-experience-xeon.html#gs.36q4lk
- Ollama. (n.d.). Ollama. https://ollama.com/
- AI Accelerated Intel® Xeon® Scalable Processors Product Brief. (n.d.). Intel. https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/ai-accelerators-product-brief.html
- Intel® Gaudi® AI Accelerator products. (n.d.). Intel. https://www.intel.com/content/www/us/en/products/details/processors/ai-accelerators/gaudi-overview.html
- Confidential Computing Solutions — Intel. (n.d.). Intel. https://www.intel.com/content/www/us/en/security/confidential-computing.html
- What is a Trusted Execution Environment? (n.d.). Intel. https://www.intel.com/content/www/us/en/content-details/788130/what-is-a-trusted-execution-environment.html
- Adeojo, J. (2023, December 3). GPT-4 Debates Open Orca-2–13B with Surprising Results! Medium. https://pub.aimind.so/gpt-4-debates-open-orca-2-13b-with-surprising-results-b4ada53845ba
- Data Centric. (2023, November 30). Surprising Debate Showdown: GPT-4 Turbo vs. Orca-2–13B — Programmed with AutoGen! [Video]. YouTube. https://www.youtube.com/watch?v=JuwJLeVlB-w
The AI Developer’s Dilemma: Proprietary AI vs. Open Source Ecosystem was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










 English (US)
English (US)