 1 day ago
2
1 day ago
2
Club.noww.in
 Image by Tumisu from Pixabay
Image by Tumisu from PixabayWhy Your Service Engineers Need a Chatbot: The Future of Troubleshooting
As part of the AI Sprint 2024, I built a multimodal chatbot with Gemini 1.5 and here’s how it can revolutionize appliance support
Across industries, effective troubleshooting is crucial for maintaining smooth operations, ensuring customer satisfaction, and optimizing the efficiency of service processes. However, troubleshooting appliances on-site can be a challenging task. With various models and countless potential issues, service engineers often find themselves sifting through manuals or searching online for solutions, an approach that can be both frustrating and time-consuming.
This is where chatbots equipped with comprehensive servicing knowledge and access to the latest troubleshooting manuals can transform the experience. While one might assume that Retrieval-Augmented Generation (RAG) would be an ideal solution for such tasks, it often falls short in this scenario. This is because these handbooks often contain elements such as tables, images, and diagrams, which are difficult to extract and summarization may miss the knotty details typically found in them, making it unfit for production rollout.
In this article, we will work towards building a chatbot using Gemini to help onsite service engineers find the right information in a faster, more intuitive manner. We will also explore the advanced features offered by Gemini, such as context caching and File API integration for multimodal prompting. In the end, we will wrap this chatbot in a Streamlit interface, for easier interaction.
Before you Begin
To build the chatbot, we’ll be using Gemini, Python 3, and Streamlit. Start by installing Streamlit on your local machine by running the below command:
pip install streamlitFor the database, we’ll rely on SQLite which comes preinstalled with Python. We will also need a Gemini API key to run inferences using Gemini 1.5 Flash. If you don’t have an API key yet, you can create one for free from this link. Once you have set up your key, install the Google AI Python SDK by running:
pip install google-generativeaiYou can find the source code & additional resources on my GitHub repo here
Acknowledgement:Google Cloud credits are provided for this project, as part of #AISprint 2024
Architecture
Before the implementation, let us examine the system architecture in detail. The process begins by fetching the required product manual from a database and passing it to Gemini. This acts as the knowledge base for our chatbot, providing essential troubleshooting information for the selected appliance.
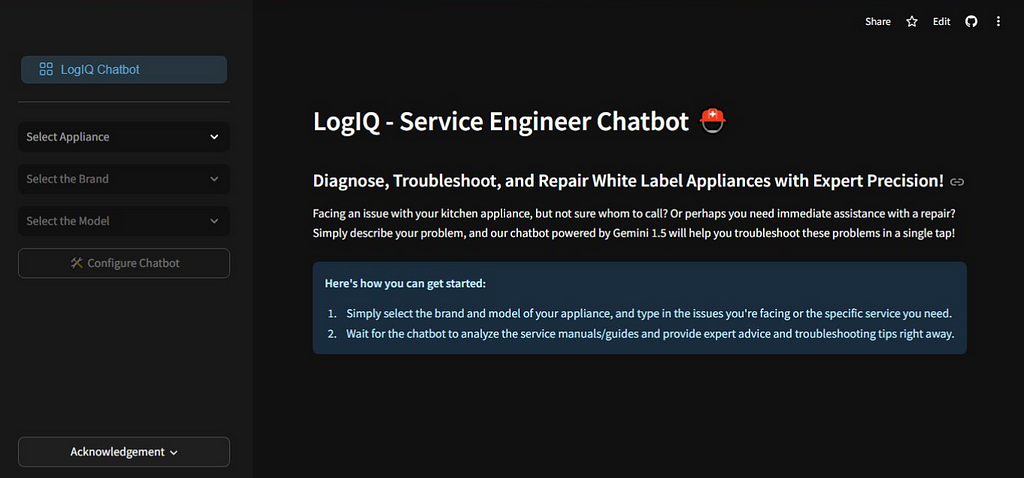 Image by Author
Image by AuthorOnce the documents are loaded, we leverage Gemini’s multimodal document processing capabilities to extract the required information from the product manual. Now, when a user interacts with the chatbot, the model combines the uploaded service manual data, chat history, and other contextual cues to deliver precise and insightful responses to the user’s queries.
To enhance performance, we’ll implement context caching, which optimizes response time for recurring queries. Finally, we’ll wrap this architecture in a simple yet intuitive Streamlit web application, allowing service engineers to seamlessly engage with the chat agent and access the information they need.
Loading Service Manuals into the Database
To begin building the chatbot, the first step is to load the troubleshooting guides into our database for reference. Since these files are unstructured in nature, we can’t store them directly in our database. Instead, we store their filepaths:
class ServiceGuides:def __init__(self, db_name="database/persistent/general.db"):
self.conn = sqlite3.connect(db_name)
self.create_table()
def add_service_guide(self, model_number, guide_name, guide_file_url):
cursor = self.conn.cursor()
cursor.execute('''
INSERT INTO service_guides (model, guide_name, guide_url)
VALUES (?, ?, ?)
''', (model_number, guide_name, guide_file_url))
self.conn.commit()
def fetch_guides_by_model_number(self, model_number):
cursor = self.conn.cursor()
cursor.execute(
"""SELECT guide_url FROM service_guides WHERE model = ?""",
(model_number,),
)
return cursor.fetchone()
In this project, we’ll store the manuals in a local directory, and save their file paths in a SQLite database. For better scalability however, its recommended to use an object storage service, such as Google Cloud Storage to store these files & maintain URLs to the files in a database service like Google Cloud SQL
Building the Conversational Agent with Gemini
Once the product manual is loaded into the database, the next step is to build the agent using 1.5 Flash. This lightweight model is part of the Gemini family and has been fine-tuned through a process known as “distillation,” where the most essential knowledge and skills from a larger model are transferred to a smaller, more efficient model to support various high-volume tasks at scale.
 Image from The Keyword by Google
Image from The Keyword by GoogleOptimized for speed and operational efficiency, the 1.5 Flash model is highly proficient in multimodal reasoning and features a context window of up to 1 million tokens, making it the ideal choice for our service engineer’s use case.
Multimodal Document Processing with 1.5 Flash
To run inference on our service manuals, we first need to upload the files to Gemini. The Gemini API supports uploading media files separately from the prompt input, enabling us to reuse files across multiple requests. The File API supports up to 20 GB of files per project, with a maximum of 2 GB per file:
class ServiceEngineerChatbot:def __init__(self):
genai.configure(api_key=st.secrets["GEMINI_API_KEY"])
def post_service_guide_to_gemini(self, title, path_to_service_guide):
service_guide = genai.upload_file(
path=path_to_service_guide,
display_name=title,
)
while service_guide.state.name == 'PROCESSING':
print('Waiting for file to be processed.')
time.sleep(2)
service_guide = genai.get_file(service_guide.name)
return service_guide
To upload a file, we use the upload_file() method, which takes as parameter the path (path to the file to be uploaded), name (filename in the destination, defaulting to a system-generated ID), mime_type (specifying the MIME type of the document, which’ll be inferred if unspecified), and the display_name.
Before proceeding, we need to verify that the API has successfully stored the uploaded file by checking its metadata. If the file’s state is PROCESSING, it cannot yet be used for inference. Once the state changes to ACTIVE, the file is ready for use. A FAILED state, indicates file processing was unsuccessful.
Conversational Response Generation
After uploading the service manual, the next step is to leverage Gemini 1.5’s multimodal document processing capabilities for response generation. The chat feature of the API allows us to collect multiple rounds of questions and responses, facilitating in-depth analysis of issues & step-by-step resolution.
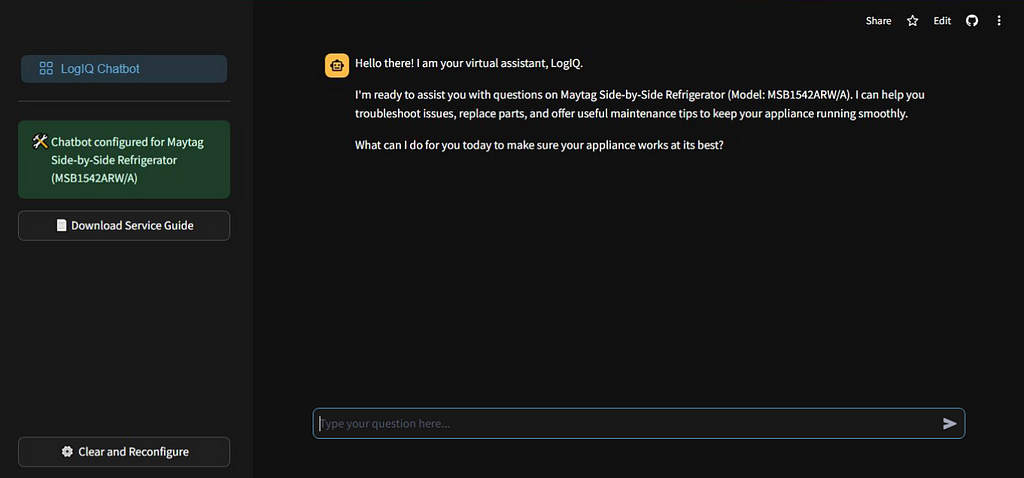 Image by Author
Image by AuthorWhen initializing the model, it’s important to provide specific guidelines and context to shape the chatbot’s behavior throughout the interaction. This is done by supplying system instruction to the model. System instructions help maintain context, guide the style of interaction, ensure consistency, and set boundaries for the chatbot’s responses, while trying to prevent hallucination.
class ServiceEngineerChatbot:def __init__(self):
genai.configure(api_key=st.secrets["GEMINI_API_KEY"])
def construct_flash_model(self, brand, sub_category, model_number):
model_system_instruction = f"""
Add your detailed system instructions here.
These instructions should define the chatbot's behavior, tone, and
provide any necessary context. For example, you might include
guidelines about how to respond to queries, the structure of
responses, or information about what the chatbot should and should
not do. Checkout my repo for this chatbot's system instructions.
"""
model_generation_cofig = genai.types.GenerationConfig(
candidate_count=1,
max_output_tokens=1500,
temperature=0.4,
),
model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
system_instruction=model_system_instruction,
generation_config=model_generation_cofig,
)
return model
We can further control the model’s response generation by tuning the model parameters through the GenerationConfig class. In our application, we’ve set the max_output_tokens to 1500, defining the maximum token limit for each response, and the temperature to 0.4, to maintain determinism in the response.
Long context optimization with Context Caching
In many cases, especially with recurring queries against the same document, we end up sending the same input tokens repeatedly to the model. While this approach may work, it's not optimal for large-scale, production-level rollouts
This is where Gemini’s context caching feature becomes essential, offering a more efficient solution by reducing both costs and latency for high-token workloads. With context caching, instead of sending same input tokens with every request, we can refer to the cached tokens for the subsequent requests
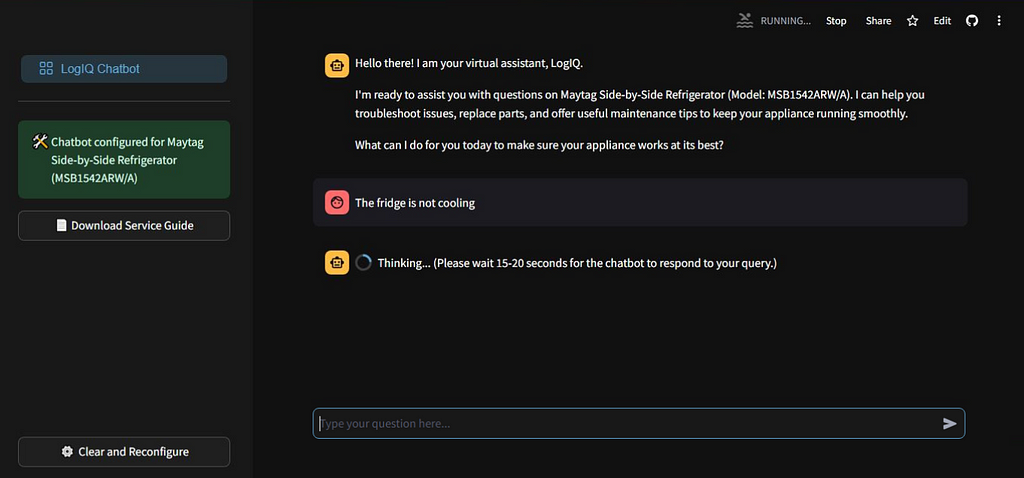 Image by Author
Image by AuthorIn this project, we cache both the system instruction and the service manual file. At scale, using cached tokens significantly reduces the cost compared to repeatedly passing the same data. By default the Time-to-Live (TTL) for these cached tokens is 1 hour, though it can be adjusted as required. Once the TTL expires, the cached tokens are automatically removed from Gemini’s context
class ServiceEngineerChatbot:def _generate_context_cache(
self,
brand,
sub_category,
model_number,
service_guide_title,
service_guide,
ttl_mins=70,
):
context_cache = caching.CachedContent.create(
model='models/gemini-1.5-flash-001',
display_name=f"{service_guide_title}_cache",
system_instruction=model_system_instruction,
contents=[
service_guide
],
ttl=datetime.timedelta(
minutes=ttl_mins
),
)
return context_cache
It’s important to note that context caching is only available for an input token count of 32,768 or more. If token count is below this threshold, you’ll need to rely on the standard multimodal prompting capabilities of Gemini 1.5 Flash.
Integrating Chatbot with Streamlit
With our chatbot’s response generation capabilities in place, the final step is to wrap it in a Streamlit app to create an intuitive user interface for the users.
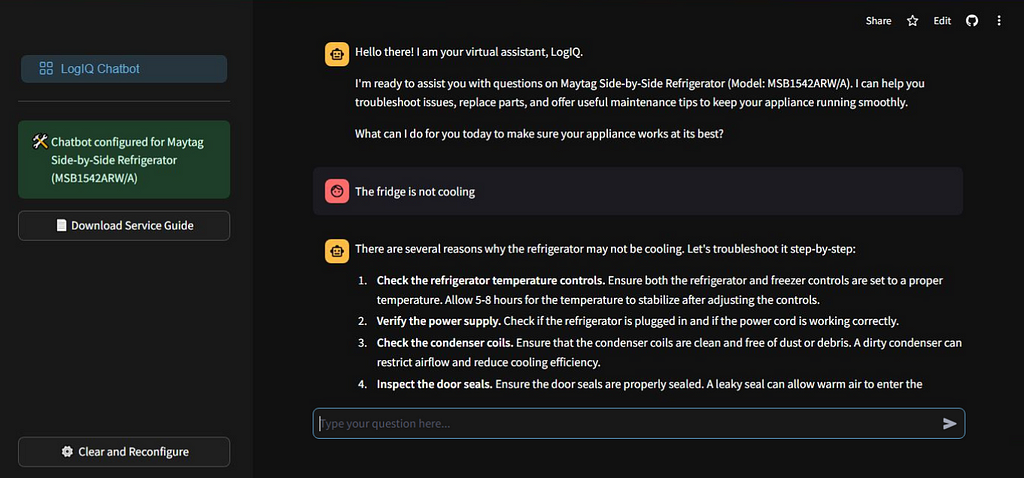 Image by Author
Image by AuthorThe interface features a dropdown where the users can select the brand, and model of the appliance they are working with. After making the selection & clicking the “Configure chatbot” button, the app will post the corresponding service manual to Gemini and present the chat interface. From thereon, the engineer can enter their queries & the chatbot will provide relevant response
Future Scope
Looking ahead, there are several promising directions to explore. The future iterations of the chatbot could integrate voice support, allowing engineers to communicate more naturally with the chatbot to get their queries addressed.
Additionally, expanding the system to incorporate predictive diagnostics can enable engineers to preemptively identify potential issues before they lead to equipment failures. By continuing to evolve this tool, the goal is to create a comprehensive support system for service engineers, ultimately improving the customer experience, thus transforming the troubleshooting eco-system
With that, we have reached the end of this article. If you have any questions or believe I have made any mistake, please feel free to reach out to me! You can get in touch with me via Email or LinkedIn. Until then, happy learning!
Why Your Service Engineers Need a Chatbot: Future of Troubleshooting was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.










 English (US)
English (US)